Data Structure Interview Questions with Answers
Data structures and algorithms are some of the most important topics for any technical interview. Most of the companies have a special interview round based on data structures and algorithms. This article contains a list of the 30 most important questions based on data structure and algorithm mostly asked in interviews.
Data Structure Interview Questions
Q1. What do you mean by data structures? What are the types of data structures?
Ans. Data structures are a way to store, manipulate and retrieve data efficiently. Data structures help to reduce every possible computation’s space and time complexity. There are mainly two types of data structures:
Linear data structures: These data structures store the data in a linear or sequential manner. Some examples of linear data structures are Arrays, Linked lists, Stacks and Queues.
Non-linear data structures: These data structures store data in a hierarchical manner instead of a sequential manner. Some examples are trees, heaps and graphs.
Q2. Define a sparse matrix.
Ans. This term is mostly defined for two-dimensional arrays. Thus, a sparse matrix is a type of matrix in which most of the elements are zero and thus we only store the non-zero values in the memory. Thus, sparse matrices help to use the space efficiently.
Q3. Define a linked list. How can you calculate the number of nodes in a linked list?
Ans. A linked list is a collection of elements known as nodes. It is a linear data structure. In a linked list, we don’t actually store data contiguously. Rather, we maintain the linear order with the help of pointers.
To calculate the number of nodes in a linked list, we first need to traverse the list and count the nodes on the way.
The code to count the number of nodes is:
struct Node{ //Defining a node
int key;
struct Node* Next;
};
struct Node* Head;
void main(){
struct node* temp = Head;
int count=0;
while(temp != NULL){
temp = temp->Next;
count++;
}
printf("\n Total nodes are %d",count);
return 0;
}
Q4. Given a linked list, how can you print its data elements in reverse order without actually reversing the linked list?
Ans. To print the linked list in reverse order without actually reversing the direction of pointers, we need to make use of recursion. The code for doing so is given as:
struct Node{ //Defining a node
int key;
struct Node* Next;
};
struct Node* Head;
reverse_print(struct Node* ptr){
if(ptr != NULL){
reverse_print(ptr->Next);
printf("%d", ptr->key);
}
}
void main(){
reverse_print(Head);
return 0;
}
Q5. What are the ways to implement a stack in data structures?
Ans. There are two ways to implement stack:
- Using arrays
- Using a linked list
Array Implementation:
#define SIZE 6 //SIZE is the total stack capacity
#include<stdio.h>
int TOP = -1 //Global variable
int Stack[SIZE]; //Declaring an array named Stack having size 6
void push_into_stack(int key)
{
if(top == SIZE-1) //When stack is full
{
print("Overflow");
return;
}
top = top+1;
stack[top] = key; //Inserting the element
}
int pop()
{
int temp; //To store the element to be deleted
if(top == -1) //If stack is empty
{
print("Overflow");
break;
}
temp = stack[top];
top = top-1;
return temp;
}
bool IsEmpty() {
if(top == -1)
return true;
else
return false;
}
void main(){
push_into_stack(10);
push_into_stack(20);
push_into_stack(30);
pop();
push_into_stack(40);
pop();
pop();
IsEmpty();
return 0;
}
Linked list Implementation:
#include <stdio.h>
struct Node{ //Defining a node
int key;
struct Node* Next;
};
struct Node* Head;
void push_into_stack(int key) //Push operation using linked list
{
struct Node *Ptr =(struct Node*)malloc(sizeof(struct Node));
if(Ptr == NULL)
{
printf("New value can't be inserted");
}
else
{
printf("Enter the value");
scanf("%d",&key);
if(Head==NULL)
{
Ptr->key = key;
Ptr->Next = NULL;
Head = Ptr;
}
else
{
Ptr->key = key;
Ptr->Next = Head;
Head = Ptr;
}
printf("push() operation successfully executed");
}
}
void pop() //Pop operation from the stack using linked list
{
int key;
struct Node *Ptr;
if (Head == NULL)
printf("Stack is empty");
else
{
key = Head->data;
Ptr = Head;
Head = Head->Next;
free(Ptr);
printf("pop() Operation successful!");
}
}
void display() //Printing all the nodes in the stack
{
int i;
struct node *temp;
temp = Head;
if(temp == NULL)
{
printf("Stack is empty");
}
else
{
printf("the elements in the Stack are \n");
while(tempmp != NULL)
{
printf("%d",temp->data);
temp = temp->next;
}
}
}
Q6. Convert the following expression from infix to postfix using stack: A+(B*C-D).
Ans. Its done as below:
| Character | Stack | Postfix |
| A | A | |
| + | + | A |
| ( | +( | A |
| B | +( | AB |
| * | +(* | AB |
| C | +(* | ABC |
| – | +(- | ABC* |
| D | +(- | ABC*D |
| ) | + | ABC*D- |
| ABC*D-+ |
Q7. What is an expression tree? Explain with the help of an example.
Ans. An expression tree denotes all the operators and variables for a particular expression. Thus, an expression tree is a tree in which
- Non-leaf node is always the operator;
- The leaf node is always the variable/constant.
For example, Suppose we have an infix expression: a+b^c-d*e^f.
Its expression tree will be:
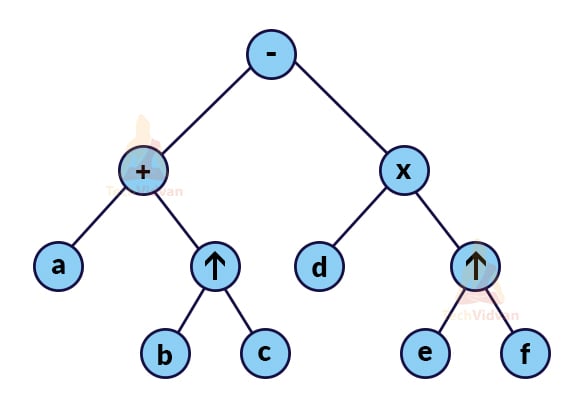
Q8. What is a priority queue? How can we implement a priority queue using arrays?
Ans. A priority queue is a special kind of queue in which we associate each element of the queue with a priority value and execute the queue according to the assigned priority. If two or more elements have the same priority, we operate them according to their order in the queue. We can implement a priority queue either by using a linked list or a 2-D array.
Implementing priority queue using a 2-D array:
While implementing a priority queue using a 2-D array, we assign column-number equivalent to the indices of the queue and the row number equivalent to the priority of the queue as shown:
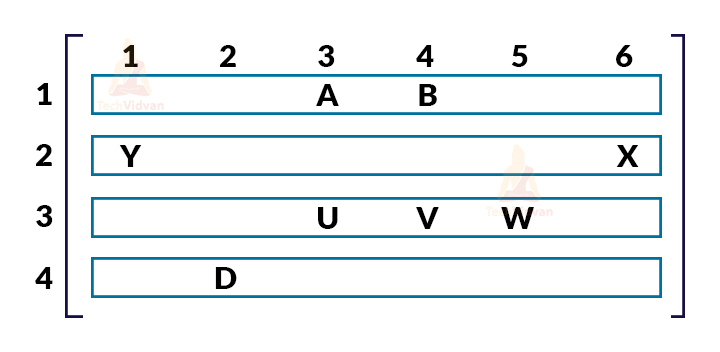
Here, A, B, D, U, V, W, X, Y are the elements of the queue.
In every row, a queue is maintained having the priority equal to the row number.
Q9. Which data structure is used to implement the concept of LRU cache?
Ans. LRU stands for Least Recently Used cache. It tells about those elements that haven’t been used for the longest by the CPU. we can make use of two data structures to implement LRU cache:
1. Queue: In a queue, we determine the maximum size of the queue by the total number of frames available. Consequently, the total number of available frames decides the available cache size. A queue follows FIFO i.e. first in first out approach. So, in a queue, the pages present at the rear will be the most recently used whereas the pages present at the front are the least recently used.
2. Hashmap: A hash table stores two things: the key value and the address of the corresponding node. Thus, in a hash map, we can store the page number in the form of a key value. This will help to tell which key was most recently used and which was the least recently used.
Q 10. Define a two-way merge sort technique.
Ans. It is a bottom-up approach. In a 2-way merge sort, we consider that every single element is sorted in itself. Then, we compare these elements and finally get a sorted list.
For example:
Consider 8 elements: 4, 2, 6, 8, 1, 7, 3, 5. We consider that all of them are sorted in themselves i.e. we have 8 sorted lists of one element each. Now, we will follow a bottom-up approach as shown:
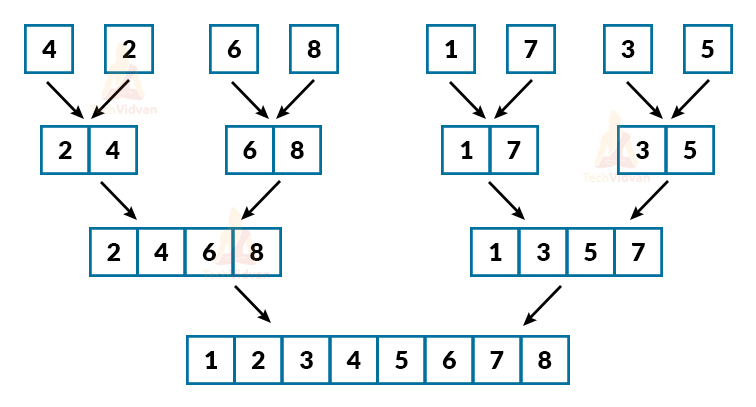
Q11. What are some of the advantages of quick sort over merge sort?
Ans. Advantages of Quick sort as below:
1. Quicksort does not take any extra space. Thus, it is an inplace sorting technique. An inplace sorting is a kind of sorting whose space complexity is not more than O(n). Quicksort does not require additional memory which makes its space complexity O(n).
2. Quicksort provides cache friendliness because it is inplace. This helps it provide more locality of reference. The locality of reference means the ability to access the same set of values again and again. This is the reason why we prefer quicksort over merge sort for the sorting of arrays.
3. Tail recursion elimination makes quicksort a very fast and efficient algorithm. Modern-day compilers are very efficient in performing tail recursion optimization. Any recursive algorithm makes use of the stack. With the help of the tail recursion method, we can prevent the last function call thus making it easier and faster for the stack. In this way, we can reduce computational time and space complexity.
Q 12. Which sorting technique should we use when swapping is a costly operation and why?
Ans. Selection sort works best when swapping is a costly operation because in any case, selection sort will perform swapping in not more than O(n) time. Selection sort selects the minimum element from the array of size ‘n’ and swaps it with the first position. Then, it selects the second smallest element and swaps it to the second position in the array. In this way, it sorts the complete array.
In the case of selection sort, the number of swaps for an array of size n is always n-1 irrespective of the size of the array or the best/average/worst case. Thus, in any case, the time complexity for performing the swap operation in selection sort is O(n). However, in other sorting techniques, the time complexity for performing swapping may exceed O(n). Therefore, if swapping is a costly operation, we always prefer a selection sort.
Q 13. What do you understand by randomized quicksort? What is the worst-case complexity to sort ‘n’ numbers using randomized quicksort?
Ans. Randomized quicksort is an extension of simple quicksort where the pivot is chosen randomly. In randomized quicksort, the position of pivot is not fixed. We select a random number as a pivot element in every iteration so as to achieve the best possible computational time.
Randomized quicksort further helps to improve the computational time to as far as O(n log n) in the best case. In the worst-case, the time complexity of randomized quicksort is O(n2). However, making use of randomized quicksort reduces the chances of reaching the worst-case.
Q 14. What is the maximum and the minimum number of nodes in a binary tree of height ‘h’?
Ans. The maximum number of nodes in a binary tree of height ‘h’ is 2h+1-1 whereas the minimum number of nodes are h+1.
Q 15. What is the maximum and the minimum number of nodes in a complete binary tree of height ‘h’?
Ans. The maximum number of nodes in a complete binary tree of height ‘h’ is 2h+1-1. The minimum number of nodes in a complete binary tree of height ‘h’ is 2h.
Q 16. What is the relationship between the number of leaf nodes and the number of internal nodes in a k-ary tree?
Ans. A k-ary tree is a tree in which every internal node has exactly ‘k’ children. Let ‘L’ be the number of leaf nodes in a k-ary tree and ‘I’ be the number of internal nodes. Then, L = (k-1)I + 1.
Q 17. Describe a recursive function to count the total number of nodes in a binary tree.
Ans. The recursive function for counting the total number of nodes in a binary tree is given as follows:
int total_nodes(struct node* ptr){
if(ptr == NULL)
return 0;
return 1 + total_nodes(ptr->left) + total_nodes(ptr->right)
}
Q 18. What is the number of unlabelled binary tree structures with 4 nodes?
Ans. The number of unlabelled nodes in a binary tree is given by the Catalan number. For a binary tree having ‘n’ nodes, the number of unlabelled nodes will be 2nCn/(n+1).
Thus, for 4 nodes, the number of unlabelled structures is 14.
Q 19. How many binary trees are possible if we are given the preorder and inorder traversal for the tree?
Ans. Only one unique binary tree is possible for a particular pre-order and inorder traversal of the tree.
Q 20. A binary search tree has the following keys: 50, 15, 62, 5, 20, 58, 91, 3, 8, 7, 37, 60, 24. What is the number of nodes in the left as well as the right subtree?
Ans. In a binary search tree, the nodes in the left subtree are smaller than the root node and the nodes in the right subtree are larger than the root node. Here, 50 is the median node, so it will be the root node. Thus all the nodes smaller than 50 are the part of the left subtree and all the nodes having values greater than 50 are the part of the right subtree. Thus, nodes on the left subtree will be 15, 5, 20, 3, 8, 7, 24, 37. The nodes in the right subtree are 62, 58, 91, 60.
So, there are 8 nodes in the left subtree and 4 nodes in the right subtree.
Q 21. What are the two different ways to represent a graph?
Ans. Graph representation tells us about the way a graph is being implemented. The complexity of any graph-based algorithm depends on this factor i.e. the way of implementing a graph. Thus, representation becomes important.
There are mainly two types of graph representations:
- Adjacency matrix representation
- Adjacency list representation
Adjacency matrix representation: In this form of a graph representation, we create a n*n matrix that shows the mapping between various vertice and edges. The rows and columns represent the vertices of the graph. If the value of A[i][j] is zero, then no edge is present between the vertices. If the value is 1, then an edge is present between that set of vertices. For example,
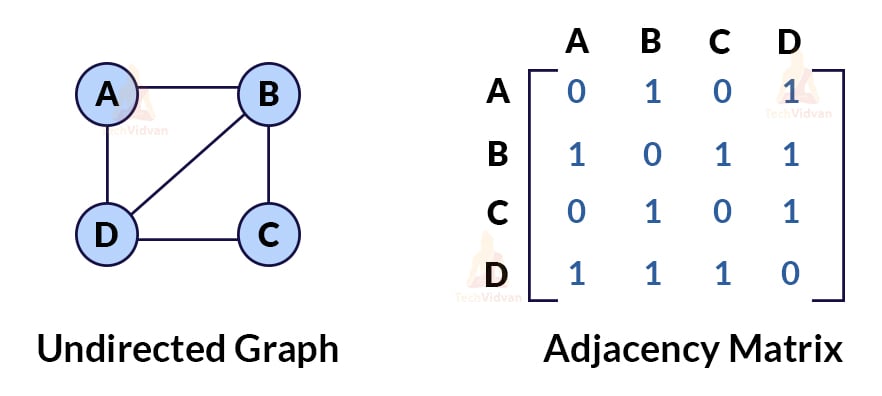
Adjacency list representation: This representation helps to display the mapping between edges and vertices with the help of a linked list. In adjacency list representation, we create an array of linked lists. Each linked list contains all the connected vertices to that particular vertex. For example,
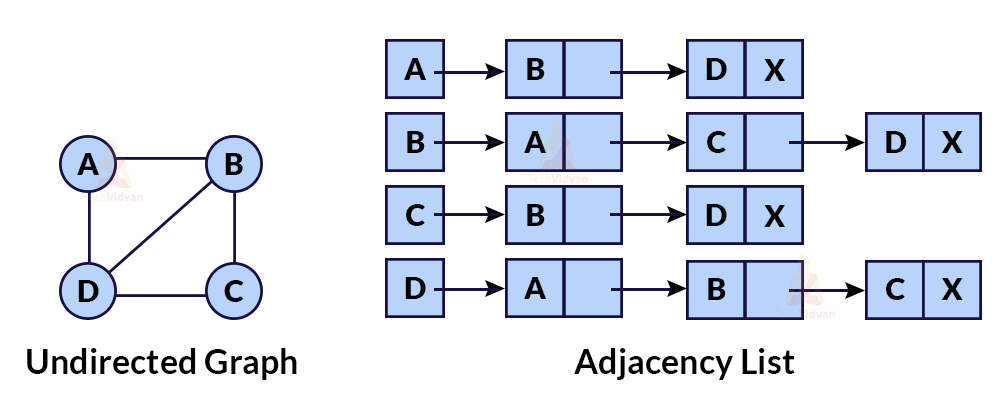
Q 22. Define topological sorting with the help of an example.
Ans. Topological sort is a linear ordering of vertices obtained by performing depth-first traversal on a directed acyclic graph. In topological sorting, we make sure that for any directed edge (u, v), vertex u must come before vertex v while ordering.
Example: Consider the following graph:
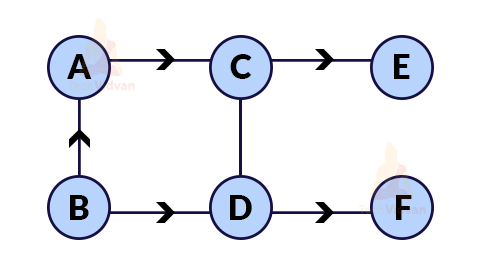
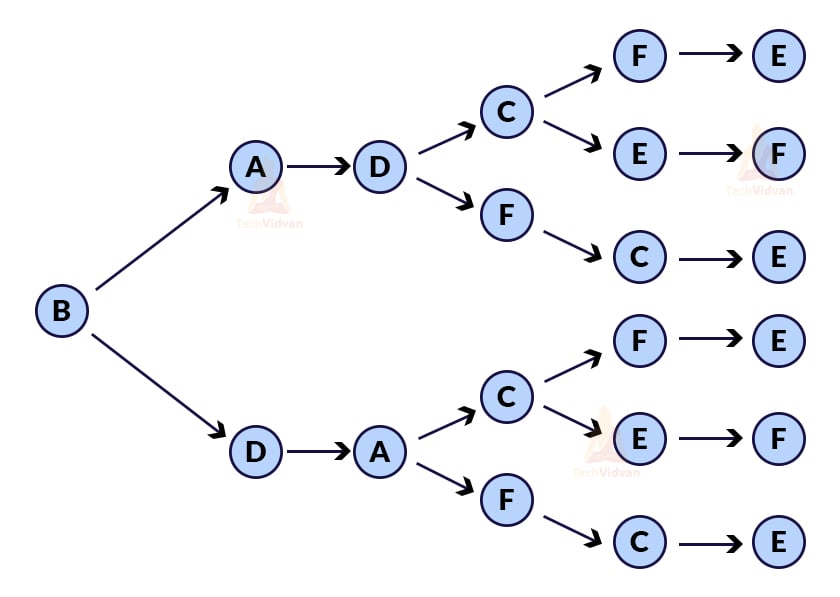
This graph will have 6 possible topological sorts as shown:
Q 23. What is an articulation point in a graph? Also, give its real-life application.
Ans. It is the vertex which if deleted, the graph will be divided into two or more non-empty components.
For example, in the following graph, if we delete the vertex labelled as 3, its edges will automatically delete.
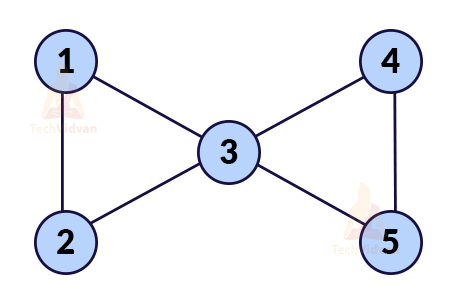
Now the graph will be:
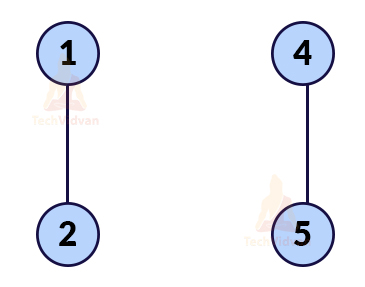
Thus, an articulation point is a vertex whose removal will divide the graph into two or more non-empty components.
The concept of articulation point is widely used in computer networks. Consider that the nodes in the above graph are the routers. So, 3 is the intermediate router. If router 3 fails, nodes of both sides won’t be able to communicate with each other.
Q 24. What are the desirable properties of an ideal hash function?
Ans.
- An ideal hash function should be easy to compute.
- For distinct keys, there must be distinct outputs.
- The keys should be uniformly distributed.
- A good hash function avoids/prevents collision.
Q 25. How can we handle collisions due to hashing in Java?
Ans. There is a special class in Java that helps to handle collisions in hashing. This class is known as Java.util.HashMap. This class helps to store the value in the linked list if more than one value has the same key. This creates a chain of values for a given key. If all the keys point to the same hashmap value, it will start behaving like a linked list and have a complexity of O(n).
Q 26. Why do we need to analyse algorithms? What are the different ways to analyse the time complexity of recursive algorithms?
Ans. A computational problem might have multiple ways to solve it. If we code in all those ways and sit with a stopwatch to measure which method takes the least time, it is known as the experimental method. But this is not a good method as it wastes a lot of our time and is machine-dependent. Thus, we need a general strategy or methodology to analyse which way is better to solve a computational problem without actually coding it. Here comes into the picture the analysis of algorithms.
To analyse recursive functions asymptotically, there are three major methods:
- Substitution method
- Master’s theorem
- Recursion tree method
Q 27. Name the algorithms used to find the minimum spanning tree in a graph.
Ans. The most commonly used algorithms for finding minimum spanning trees are:
- Prim’s Algorithm
- Kruskal’s Algorithm
Both these algorithms follow the greedy approach to find the minimum cost spanning tree.
Q 28. What is a multistage graph? How can we find the shortest path between two edges in a multistage graph?
Ans. A multistage graph is a directed graph. In a multistage graph, the vertices are arranged in an ordered way in the form of multiple stages where the first and the last stage contain only a single vertex.
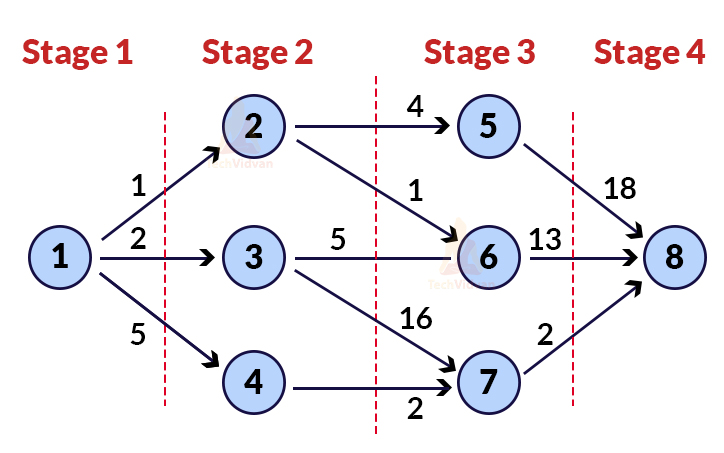
In a multistage graph, the node of stage 1 can be adjacent to the node of stage 2 and the node of stage 2 is adjacent to the node of stage 3. However, we can’t directly have an edge from stage 1 to stage 3.
Thus, to find the shortest possible distance between a node at stage 1 and a node at stage ‘L’, we make use of Bellman ford’s algorithm. This algorithm is a single source shortest path algorithm also applicable for graphs having negative edge weights.
Q 29. What is the time complexity of Kruskal’s algorithm to find a minimum cost spanning tree?
Ans. The time complexity of Kruskal’s algorithm is O(E* log E)
where E = number of edges in the graph.
Q 30. Explain the two important properties of dynamic programming. What are the applications of dynamic programming?
Ans. Dynamic programming is an optimization over recursion. The two important properties of dynamic programming are:
1. Optimal substructure: This property comes into the picture if we are getting an optimal solution of the sub-problem which we can directly include in the final solution. This property decides whether we can apply dynamic programming to a certain problem or not.
2. Overlapping sub-problems: This property is used if there are sub-problems which we need to solve again and again i.e. the sub-problems are overlapping. This property tells whether applying dynamic programming will give us an extra advantage or not.
Some of the major applications of Dynamic programming are:
- 0/1 knapsack problem
- All pair shortest path algorithms
- Finding the longest common subsequence
- Matrix chain multiplication problem
- Bellman ford’s algorithm
- Subset sum problem
Conclusion:
This article contains a few important questions that are mostly asked in programming interviews. In this article, we have tried to cover almost every important topic from data structures and algorithms and questions related to these topics.