Big Data Architecture – Learn now for Big Gains
In this article, we will study Big Data Architecture. Till now, we have seen many use-cases and case studies which shows how companies are using Big Data to gain insights.
Have you ever heard about a plan that companies make for carrying out Big Data analysis? Big Data Architecture is the most important part when a company plans for applying Big Data analytics in its business.
The article provides you the complete guide about Big Data architecture.
The article covers:
- Introduction to Big Data architectures
- Components of Architecture of Big data
- Challenges in designing Big Data architecture
- Benefits of Big Data architecture
Introduction to Big Data Architecture
Big Data architecture is a system used for ingesting, storing, and processing vast amounts of data (known as Big Data) that can be analyzed for business gains. It is a blueprint of a big data solution based on the requirements and infrastructure of business organizations.
A robust architecture saves the company money. It helps them to predict future trends and improves decision making. It is designed for handling:
- Batch processing of big data sources.
- Real-time processing of big data.
- Predictive analytics and machine learning.
Architecture of Big Data
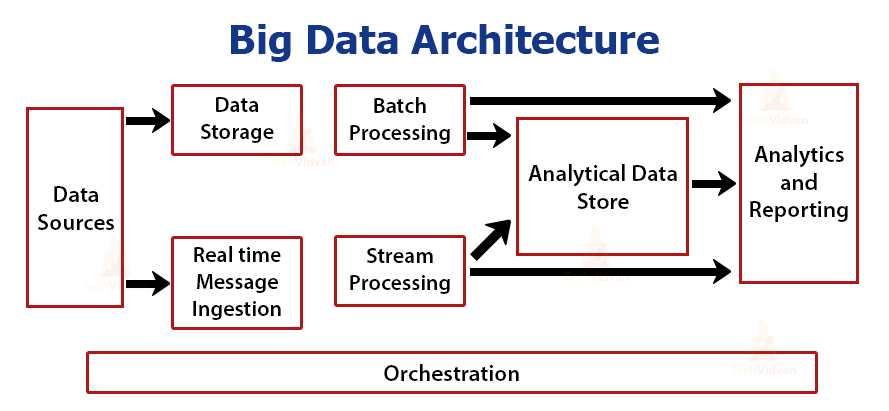
It comprises the following components:
1. Data Sources
Data sources govern Big Data architecture. It involves all those sources from where the data extraction pipeline gets built. Data Sources are the starting point of the big data pipeline.
Data arrives through multiple sources including relational databases, sensors, company servers, IoT devices, static files generated from apps such as Windows logs, third-party data providers, etc. This data can be batch data or real-time data.
Big Data architecture is designed in such a way that it handles this vast amount of data.
2. Data Storage
Data Storage is the receiving end for Big Data. Data Storage receives data of varying formats from multiple data sources and stores them. It even changes the format of the data received from data sources depending on the system requirements.
For example, Big Data architecture stores unstructured data in distributed file storage systems like HDFS or NoSQL database. It stores structured data in RDBMS.
3. Real-time Message Ingestion
We need to build a mechanism in our Big Data architecture that captures and stores real-time data that is consumed by stream processing consumers. It is simply a datastore where the new messages are dropped inside the folder.
There are a number of solutions that require the necessity of a message-based ingestion store that acts like a message buffer and supports scale based processing. They provide reliable delivery along with the other messaging queuing semantics.
It may include options like Apache Kafka, Event hubs from Azure, Apache Flume, etc.
4. Batch Processing
The architecture requires a batch processing system for filtering, aggregating, and processing data which is huge in size for advanced analytics.
These are generally long-running batch jobs that involve reading the data from the data storage, processing it, and writing outputs to the new files. The most commonly used solution for Batch Processing is Apache Hadoop.
5. Stream Processing
There is a little difference between stream processing and real-time message ingestion. Stream processing handles all streaming data which occurs in windows or streams. It then writes the data to the output sink. It includes Apache Spark, Storm, Apache Flink, etc.
6. Analytical Data Store
After processing data, we need to bring data in one place so that we can accomplish an analysis of the entire data set. The analytical data store is important as it stores all our process data at one place making analysis comprehensive.
It is optimized mainly for analysis rather than transactions. It can be a relational database or cloud-based data warehouse depending on our needs.
7. Analytics and Reporting
After ingesting and processing data from varying data sources we require a tool for analyzing the data.
For this, there are many data analytics and visualization tools that analyze the data and generate reports or a dashboard. Companies use these reports for making data-driven decisions.
8. Orchestration
Moving data through these systems requires orchestration in some form of automation.
Ingesting data, transforming the data, moving data in batches and stream processes, then loading it to an analytical data store, and then analyzing it to derive insights must be in a repeatable workflow. This allows us to continuously gain insights from our big data.
Challenges in Designing Big Data Architecture
1. Data Quality
Data quality is a challenge while working with multiple data sources. The architecture must ensure data quality. The data formats must match, no duplicate data, and no data must be missed.
The architecture must be designed in such a way that it analyses and prepares the data before bringing data together with other data for analysis.
2. Scaling
Big Data architecture must be designed in such a way that it can scale up when the need arises. Otherwise, the system performance can degrade significantly.
3. Security
Data Security is the most crucial part. It is the biggest challenge while dealing with big data. Hackers and Fraudsters may try to add their own fake data or skim companies’ data for sensitive information.
Cybercriminal would easily mine company data if companies do not encrypt the data, secure the perimeters, and work to anonymize the data for removing sensitive information.
4. Choosing Technology set
There are many tools and technologies with their pros and cons for big data analytics like Apache Hadoop, Spark, Casandra, Hive, etc. Choosing the right technology set is difficult.
Companies must be aware that whether they need Spark or the speed of Hadoop MapReduce is enough. Also they must know whether to store data in Cassandra, HDFS, or HBase.
5. Paying loads of money
Big data architecture entails lots of expenses. During architecture design, the Big data company must know the hardware expenses, new hires expenses, electricity expenses, needed framework is open-source or not, and many more.
Benefits of Big Data Architecture
1. Reducing costs: Big data technologies such as Apache Hadoop significantly reduce storage costs.
2. Improve decision making: The use of Big data architecture streaming component enables companies to make decisions in real-time.
3. Future trends prediction: Big Data analytics helps companies to predict future trends by analyzing big data from multiple sources.
4. Creating new Products: Companies can understand the customer’s requirements by analyzing customer previous purchases and create new products accordingly.
Summary
Big Data architecture is a system for processing data from multiple sources that can be analyzed for business purposes.
It comprises Data sources, Data storage, Real-time message ingestion, Batch Processing. It also includes Stream processing, Data Analytics store, Analysis and reporting, and orchestration.
The company faces some challenges like data quality, security, and scaling while designing Big Data architecture. Big Data architecture reduces cost, improves a company’s decision making, and helps them to predict future trends.