Machine Learning Project – Speech Emotion Recognition
Speech Emotion Recognition (SER) is a dynamic field at the intersection of human-computer interaction and affective computing, dedicated to deciphering emotional states conveyed through speech. By integrating signal processing, machine learning, and psychology principles, SER seeks to untangle the intricate link between vocal expressions and emotions. With the rise of digital platforms and virtual assistants, there’s a growing demand for systems capable of accurately understanding and responding to human emotions.
In this project, we explore SER using advanced techniques in audio signal processing and machine learning to create a robust framework for automatically classifying emotional states from speech recordings. Leveraging datasets like the Ryerson Audio-Visual Database of Emotional Speech and Song (RAVDESS), we aim to develop a model showcasing high emotion classification accuracy and demonstrate practical, real-world applications. Through this endeavor, we strive to contribute to the field of affective computing, enhancing human-computer interaction by decoding the nuances of emotions in speech.
About Machine Learning Speech Emotion Recognition
This project delves into speech emotion recognition (SER), a fascinating area intersecting human-computer interaction and affective computing. SER aims to discern and interpret emotional states conveyed through speech signals, employing principles from signal processing, machine learning, and psychology. Leveraging advanced techniques in audio signal processing and machine learning, we developed a robust framework capable of automatically classifying emotional states from speech recordings.
Prerequisites For Machine Learning Speech Emotion Recognition
Python Programming: A strong understanding of Python programming language is essential, as the project relies on libraries and modules such as NumPy, scikit-learn, librosa, soundfile, and matplotlib, which are commonly used in machine learning and signal processing tasks.
Machine Learning Fundamentals: Students must be familiar with machine learning concepts such as classification algorithms, feature extraction techniques, model evaluation metrics, and data preprocessing. This includes an understanding of supervised learning, particularly classification tasks.
Signal Processing Basics: Understanding signal processing concepts such as Fourier transforms, spectrograms and Mel-Frequency Cepstral Coefficients (MFCCs) will help you understand the feature extraction process from audio signals.
Data Handling and Analysis: Proficiency in data handling and analysis using libraries like Pandas for data manipulation and exploration is required, as the project involves processing and analyzing audio data.
Download Machine Learning Speech Emotion Recognition Project
Please download the source code of Machine Learning Speech Emotion Recognition Project: Machine Learning Speech Emotion Recognition Project Code.
About Dataset
The Ryerson Audio-Visual Database of Emotional Speech and Song (RAVDESS) comprises 1440 speech and song audio files, a subset of a larger dataset available on Zenodo. These files, representing trials conducted with 24 professional actors split evenly by gender, feature lexically matched statements delivered in a neutral North American accent. Emotions conveyed include calm, happy, sad, angry, fearful, surprise, and disgust, with varying intensity levels. Each file is uniquely identified by a seven-part numerical convention specifying modality, vocal channel, emotion, intensity, statement, repetition, and actor. For example, “03-01-06-01-02-01-12.wav” denotes an audio-only file with a speech expressing fearful emotion at average intensity, featuring the statement “dogs” in its first repetition and performed by the 12th female actor. This dataset is invaluable for emotion recognition research, with its construction and validation outlined in an Open Access paper published in PLoS ONE. Additionally, researchers can explore a complementary Kaggle dataset focusing on song emotions derived from RAVDESS.
The link to Dataset can be found: SpeechEmotionRecognition
Tools and libraries used
1. librosa: librosa is a Python library for audio and music analysis. It provides functions to extract various audio features such as MFCCs (Mel-Frequency Cepstral Coefficients), chroma features, and mel spectrograms. These features are commonly used in speech and music classification, transcription, and similarity analysis tasks.
2. soundfile: soundfile is a Python library for reading and writing sound files. It provides a simple interface for reading audio data from various formats such as WAV, FLAC, and OGG and also allows for writing audio data to these formats. It is often used in conjunction with librosa to load audio files.
3. os, glob: os, and glob are Python standard libraries used for the operating system and file system operations. os provides functions to interact with the operating system, such as navigating directories, while glob helps match file path patterns.
4. pickle: pickle is a module used for serializing and deserializing Python objects. It allows objects to be converted into a byte stream, saved to a file, and later loaded back into memory. In the context of the code snippet, it might be used to save and load trained machine-learning models.
5. numpy: numpy is a fundamental package for scientific computing in Python. It supports large, multi-dimensional arrays and matrices and a collection of mathematical functions to operate on these arrays efficiently. numpy is extensively used in numerical computations, including data manipulation, linear algebra, and random number generation.
6. sklearn.model_selection.train_test_split: train_test_split is a function from the sklearn.model_selection module that splits datasets into training and testing sets. It randomly splits the data according to the specified test or train size, allowing for model evaluation on unseen data.
7. sklearn.neural_network.MLPClassifier: MLPClassifier is a class from the sklearn.neural_network module representing a Multi-Layer Perceptron (MLP) classifier. MLP is a type of feedforward artificial neural network used for classification tasks. The MLPClassifier in scikit-learn allows for training and predicting with MLP models.
8. sklearn.metrics.accuracy_score: accuracy_score is a function from the sklearn.metrics module used for evaluating classification accuracy. It compares the actual and predicted labels and returns the proportion of correct predictions.
9. sklearn.preprocessing.StandardScaler: StandardScaler is a class from the sklearn.The preprocessing module standardises features by removing the mean and scaling to unit variance. It is often used as a preprocessing step before applying machine learning algorithms to ensure that features are on the same scale.
Step-by-Step Code Implementation of ML Speech Recognition Project
The provided code helps recognise emotions in speech. Let’s break down the code and explain each step:
Let’s break down the code into various steps and explain each one:
Step 1: Feature Extraction:
import librosa
import soundfile
import os, glob, pickle
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.neural_network import MLPClassifier
from sklearn.metrics import accuracy_score
from sklearn.preprocessing import StandardScaler
# Function to extract features with additional preprocessing
def extract_feature(file_name, mfcc=True, chroma=True, mel=True, delta_mfcc=True, delta2_mfcc=True):
with soundfile.SoundFile(file_name) as sound_file:
X = sound_file.read(dtype="float32")
sample_rate = sound_file.samplerate
if chroma:
stft = np.abs(librosa.stft(X))
result = np.array([])
if mfcc:
mfccs = librosa.feature.mfcc(y=X, sr=sample_rate, n_mfcc=40)
if delta_mfcc:
delta_mfccs = librosa.feature.delta(mfccs)
if delta2_mfcc:
delta2_mfccs = librosa.feature.delta(mfccs, order=2)
mfccs = np.concatenate((mfccs, delta_mfccs, delta2_mfccs))
else:
mfccs = np.concatenate((mfccs, delta_mfccs))
result = np.mean(mfccs, axis=1)
if chroma:
chroma = np.mean(librosa.feature.chroma_stft(S=stft, sr=sample_rate), axis=1)
result = np.hstack((result, chroma))
if mel:
mel = np.mean(librosa.feature.melspectrogram(X, sr=sample_rate), axis=1)
result = np.hstack((result, mel))
return result
The extract_feature() function extracts audio features from the input audio files. Features include Mel-frequency cepstral coefficients (MFCC), chroma, and mel spectrogram. These features are commonly used in audio processing tasks such as speech recognition. The function uses the librosa library for feature extraction.
Step 2: Data Loading and Preprocessing:
emotions_ = {
'01':'neutral',
'02':'calm',
'03':'happy',
'04':'sad',
'05':'angry',
'06':'fearful',
'07':'disgust',
'08':'surprised' }
observed_emotions_ = ['calm', 'happy', 'fearful', 'disgust']
def load_data(test_size=0.2):
x_, y_ = [], []
for file_ in glob.glob(r"C:\Users\vaish\Downloads\Speech Emotion Recognition\Actor_*\*.wav"):
file_name_ = os.path.basename(file_)
emotion_ = emotions_[file_name_.split("-")[2]]
if emotion_ not in observed_emotions_:
continue
feature_ = extract_feature(file_)
x_.append(feature_)
y_.append(emotion_)
return train_test_split(np.array(x_), y_, test_size=test_size, random_state=101)
def extract_feature(file_name_, mfcc=True, chroma=True, mel=True):
X_, sample_rate_ = librosa.load(file_name_, res_type='kaiser_fast')
result_ = np.array([])
if mfcc:
mfccs_ = np.mean(librosa.feature.mfcc(y=X_, sr=sample_rate_, n_mfcc=40).T, axis=0)
result_ = np.hstack((result_, mfccs_))
if chroma:
chroma_ = np.mean(librosa.feature.chroma_stft(y=X_, sr=sample_rate_).T, axis=0)
result_ = np.hstack((result_, chroma_))
if mel:
mel_ = np.mean(librosa.feature.melspectrogram(y=X_, sr=sample_rate_).T, axis=0)
result_ = np.hstack((result_, mel_))
return result_
The load_data() function loads audio files from a specified directory, extracts features using extract_feature() function, and splits the data into training and testing sets using train_test_split() from sklearn.model_selection.
Step 3: Model Training and Evaluation:
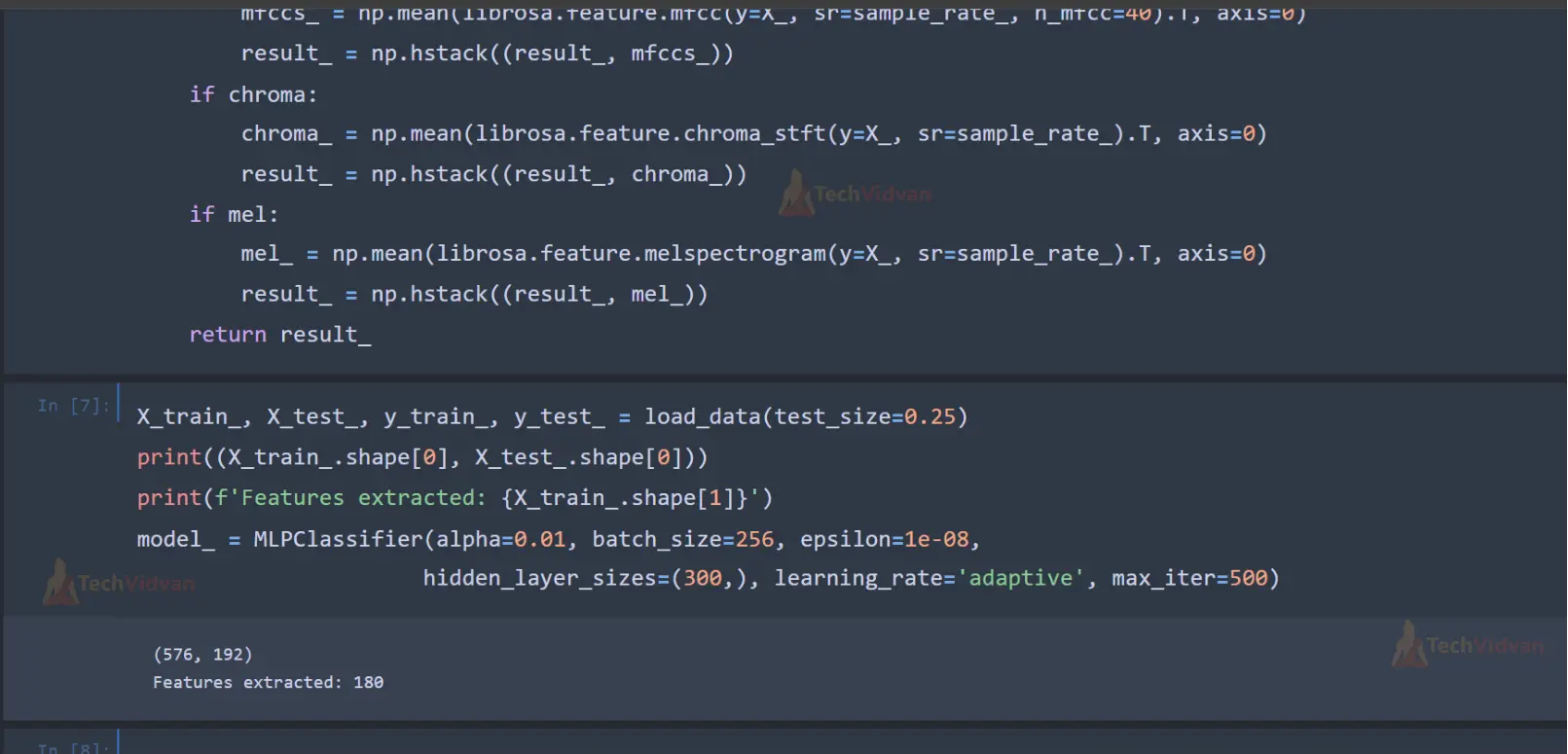
X_train_, X_test_, y_train_, y_test_ = load_data(test_size=0.25)
print((X_train_.shape[0], X_test_.shape[0]))
print(f'Features extracted: {X_train_.shape[1]}')
model_ = MLPClassifier(alpha=0.01, batch_size=256, epsilon=1e-08,
hidden_layer_sizes=(300,), learning_rate='adaptive', max_iter=500)
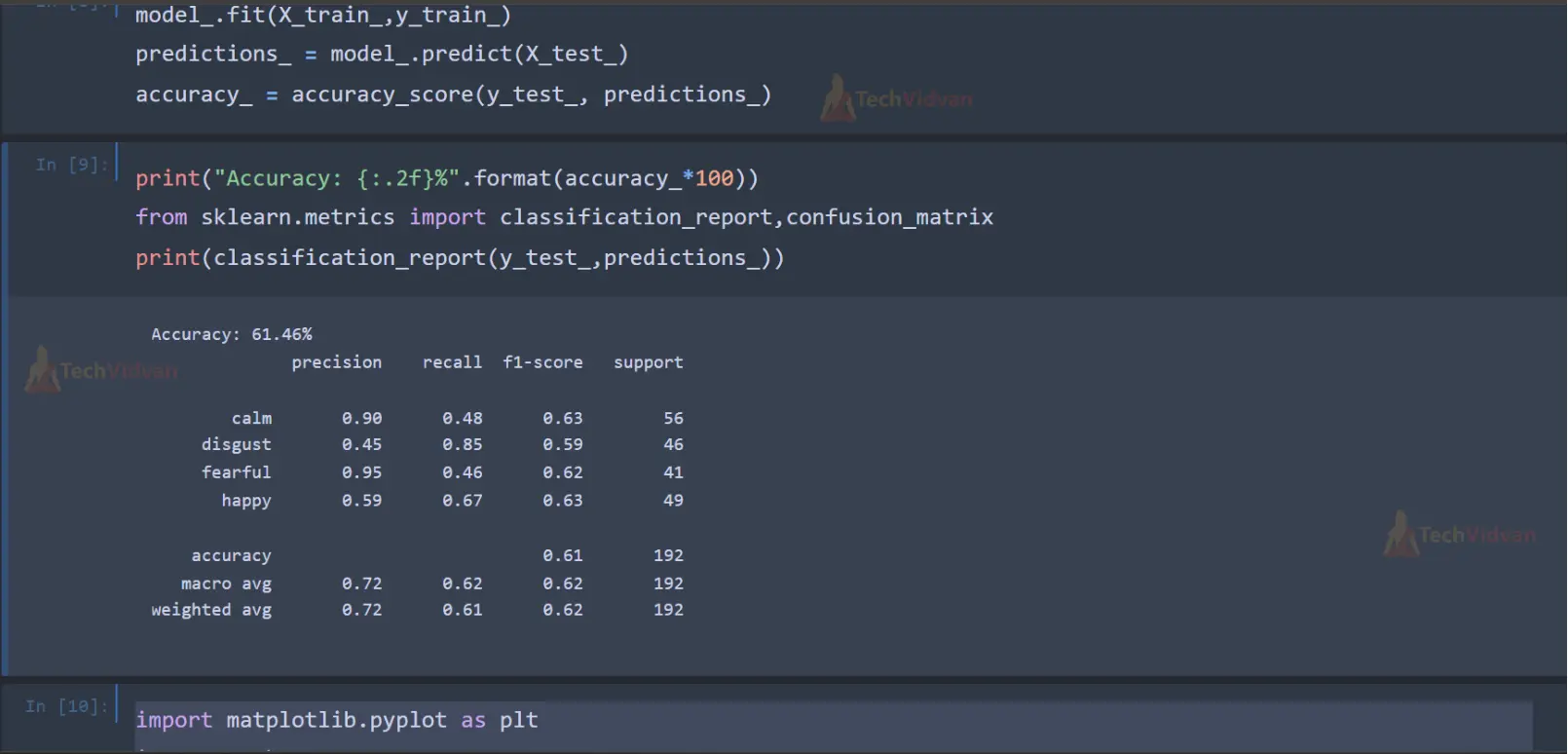
model_.fit(X_train_,y_train_)
predictions_ = model_.predict(X_test_)
accuracy_ = accuracy_score(y_test_, predictions_)
print("Accuracy: {:.2f}%".format(accuracy_*100))
from sklearn.metrics import classification_report,confusion_matrix
print(classification_report(y_test_,predictions_))
The code trains a Multi-Layer Perceptron (MLP) classifier using MLPClassifier() from sklearn.neural_network. It then evaluates the model’s performance on the testing set using accuracy score and classification report.
Output:
Step 4: Visualization
import matplotlib.pyplot as plt
import seaborn as sns
# Function to plot confusion matrix
def plot_confusion_matrix(y_true, y_pred, classes, title='Confusion matrix', cmap=plt.cm.Blues):
cm = confusion_matrix(y_true, y_pred)
plt.figure(figsize=(8, 6))
sns.heatmap(cm, annot=True, fmt='d', cmap=cmap, xticklabels=classes, yticklabels=classes)
plt.title(title)
plt.xlabel('Predicted label')
plt.ylabel('True label')
plt.show()
# Plot confusion matrix
plot_confusion_matrix(y_test_, predictions_, classes=observed_emotions_, title='Confusion Matrix')
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from collections import Counter
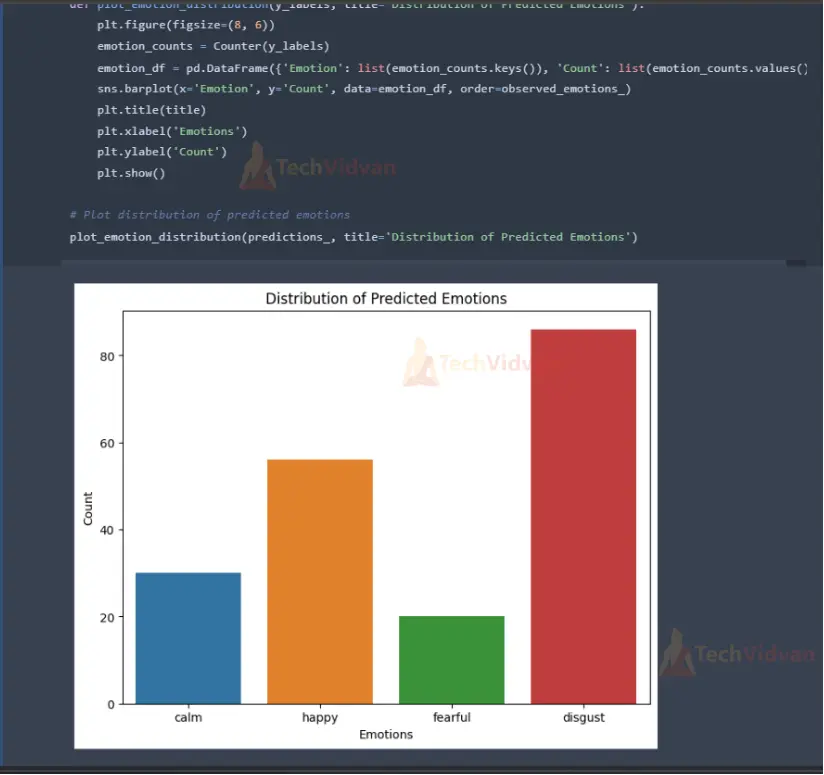
# Function to plot distribution of predicted emotions
def plot_emotion_distribution(y_labels, title='Distribution of Predicted Emotions'):
plt.figure(figsize=(8, 6))
emotion_counts = Counter(y_labels)
emotion_df = pd.DataFrame({'Emotion': list(emotion_counts.keys()), 'Count': list(emotion_counts.values())})
sns.barplot(x='Emotion', y='Count', data=emotion_df, order=observed_emotions_)
plt.title(title)
plt.xlabel('Emotions')
plt.ylabel('Count')
plt.show()
# Plot distribution of predicted emotions
plot_emotion_distribution(predictions_, title='Distribution of Predicted Emotions')
The code visualizes the confusion matrix using plot_confusion_matrix() function, which helps understand the model’s performance across different emotion classes. It also visualizes the distribution of predicted emotions using plot_emotion_distribution() function, which provides insights into the distribution of predicted emotions.
Output: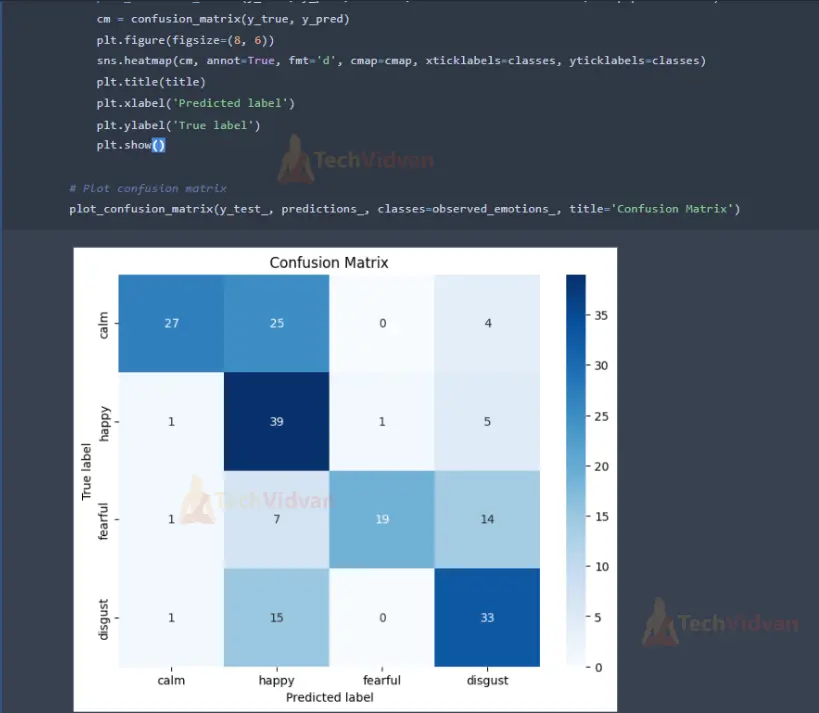
Summary
In conclusion, our exploration of Speech Emotion Recognition (SER) has unveiled the potential of advanced techniques in audio signal processing and machine learning to decode the complexities of human emotions conveyed through speech. By developing a robust framework and utilising datasets like the Ryerson Audio-Visual Database of Emotional Speech and Song (RAVDESS), we have demonstrated the efficacy of our model in accurately classifying emotional states from speech recordings. By achieving high accuracy and showcasing practical applications in domains such as mental health monitoring, customer service, and entertainment, our project underscores the significance of SER in enhancing human-computer interaction and affective computing.
Further research and refinement of SER methodologies will continue to drive innovation in understanding and responding to human emotions, ultimately fostering more empathetic and responsive systems in the digital era.
You can check out more such machine learning projects on TechVidvan.